
在人工智能和大数据分析领域,北京多闻智能科技有限公司是分布式云计算技术、NLP自然语言处理技术、非结构化数据处理技术、智能搜索引擎技术和数据建模等方面的行业领先厂商!

知行智库平台采用OpenStack和Docker相结合的模式,OpenStack主要用于管理整个数据中心,使用Docker Container作为OpenStack的补充。透过网络将庞大的计算处理程序自动分拆成无数个较小的子程序,再交由云服务器的庞大系统,经计算分析之后,将处理结果提供给用户。

多闻智能自主研发的元计算运维管理系统基于面向服务和扩展的体系架构,将原有的各类平台服务和业务功能封装为不同粒度的Restful Web API。这些服务接口覆盖所有的运维工作,包括计算资源的分配和调度、系统运行状态的监控、故障检测和告警、审计和计费系统等。这些服务也可以对外开放,使用户能够充分利用这些服务接口,提取有价值的信息或业务流程整合到用户自己的应用系统中。

多闻智能自主研发的元计算运维管理系统能够将云计算基础设施的各种资源进行虚拟化,为数据、计算能力、存储以及其他资源提供一致的逻辑视图,实现了资源的池化,并能依靠自动化的手段来对各项资源进行高效地调度、管理和分配。全新的自动化编排方案,能进行应用资源的合理分配,同时还可以将网络资源、计算资源进行切片,基于业务需求进行资源的分配和组合。

多闻智能自主研发的云计算运维管理系统认识到“唯一不变的就是变化本身”,能够做到便捷的按需定制,能够根据用户的要求量身剪裁,使系统的界面外观、功能描述、操作体验更加贴近和符合用户的既有使用习惯。并能根据用户的需求,对接用户已有的信息系统,实现数据互联互通,避免重复建设。

多闻智能自主研发的元计算运维管理系统内置轻量化、可移植、自包涵的容器引擎,客户应用可以一次构建全平台运行,系统增加了高级API,提供了能够独立运行Unix进程的虚拟化解决方案。

多闻智能自主研发的元计算运维管理系统可以根据客户业务需求和工作量规模变化,智能化管理和配置云端计算资源,帮助客户实现计算服务获取的最佳费效比。
多闻智能使用虚拟交换机技术,可以让用户可视化的规划设计计算实例之间以及对外的网络通信的路由规则,满足客户个性化的网络路由需求;并能按网络协议和端口统计网络流量,帮助客户节省网络费用,减少网络攻击风险。


多闻智能运用云防火墙为每个连接公共网络的云服务器提供一系列的防护服务,包括入侵防御系统、Web数据过滤、数据丢失防护、恶意软件过滤、威胁检测沙箱、DDOS防御等,提高用户发布到Internet的服务器访问安全性。
海量数据的存储访问,需要扩展性、伸缩性极强的分布式存储架构来实现。知行智库平台运用块存储、文件存储、对象存储等先进技术,满足了多种数据类型存取的需求,是传统数据存储方式的有力补充,帮助用户更加高效快捷的完成数据存储。

知行智库平台运用HDFS+HBase,利用HDFS的分布式、高可用数据存储,结合HBase面向列的数据存储模型,从而解决大数据量存储的问题;结合HBase基于Rowkey自然序的存储,从而实现10 bilion级数据快速查询。

知行智库平台运用NoSQL数据库,使用专有的Client API来进行访问。底层存储引擎一般使用无模式的列数据库,默认由多个Replica Set+Shard组成,当一个节点出现故障时,自动选举产生新的主节点,通过多重保障为用户提供大于99.999%的系统可用性和TPS>1000的吞吐量。

知行智库平台充分考虑对应用程序的性能表现进行提升,运用缓存机制方法,使用内存数据库实现缓存技术手段,使用Redis-Cluster来构建缓存数据存储系统,使用自定义的File Store来支持持久化。

知行智库平台基于MooseFS良好的架构系统能提供极强的扩展性和较大的吞吐量,现有基于文件系统的程序不需要做任何修改就可以使用AFS。整个架构能满足用户从视频网站到头像小文件存储等各种类型的文件存储需求。

知行智库平台用作云计算实例的磁盘存储,整个架构分为M、S和C三个部分,分别代表Master、Chunk Server和Client。可为云计算平台带来许多优良特性,如更高的数据可靠性和可用性、灵活的数据快照功能、更好的虚拟机动态迁移支持、秒级主机故障恢复时间等等。

知行智库平台运用的对象存储是为了克服块存储与文件存储各自的缺点,发扬它俩各自的优点,主要保证在读写快同时也利于共享,能够帮助用户高效的管理整合海量数据。
基于AI、模式识别、神经网络等核心技术,进行深度数据挖掘与分析。同时,加入了自然语言处理算法,通过情感分析、文本挖掘、语言建模等方式,对数据进行有效处理。
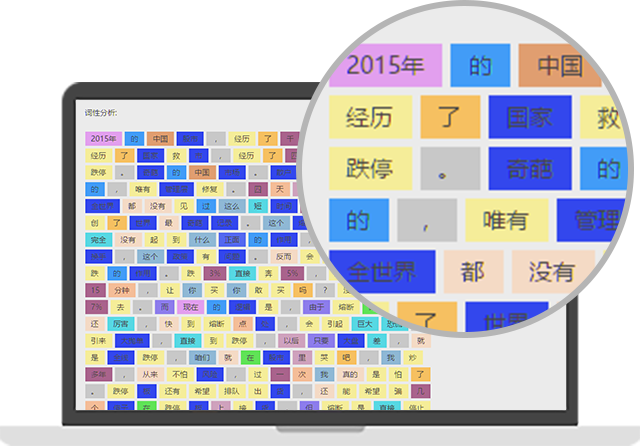
因为中文的自然语言书写对于不同的词之间不会采用显示分隔符(如空格)进行分割,在大多数自然语言问题当中,分词都作为最基础的步骤。 词性用来描述一个词在上下文中的作用,而词性标注就是识别这些词的词性,以确定其在上下文中的作用。一般情况下,词性标注是建立在分词基础上的另一个自然语言处理的基础步骤。为了适应知行智库自然语言处理的需要, 知行智库采用将分词和词性标注联合枚举的方法,实现了这一套分词和词性标注系统。
实体识别用于从文本中发现有意义的信息,例如人名、公司名、产品名、时间、地点等。 实体识别是语义分析中的重要的基础,是情感分析、机器翻译、语义理解等任务中的重要步骤。知行智库实体识别引擎基于自主研发的结构化信息抽取算法,F1分数达到80%。通过对行业语料的进一步学习,可以达到更高的准确率。


情感分析指的是对文本中情感的倾向性和评价对象进行提取的过程。知行智库情感引擎提供行业领先的篇章级情感分析。基于上百万条社交网络平衡语料和数十万条新闻平衡语料的机器学习模型,结合自主开发的学习技术,正负面情感分析准确度达到80%~85% 。经过行业数据标注学习后准确率可达85%~90%。
由于现今网络的发展,信息获取变的十分简单和方便。随之而来的弊端之一就是巨量的信息无法快速有效的处理以便后续使用。特别在新闻语料中,常出现大量重复、多余或者不重要信息的情况。对此,较直观的一种解决办法是对新闻做摘要,减少信息长度,即新闻摘要。
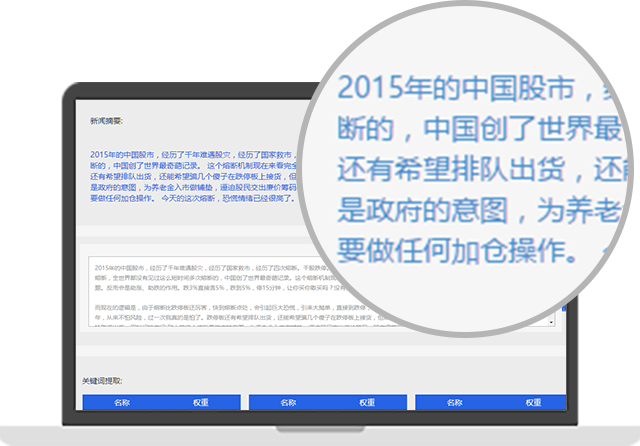

关键词作为一个对文本常用的概括,可以被应用于关键词云计算等应用上。知行智库的关键词提取引擎可以将文本自动进行关键词分析,给出每个词语相应的权重。
知行智库平台对大数据的处理技术涵盖数据采集、数据预处理、数据存储、数据分析和挖掘以及数据展现的全流程。在合适工具的辅助下,对广泛异构的数据源进行抽取和集成,结果按照一定的标准统一存储,利用先进的数据分析技术对存储的数据进行分析,从中提取有益的知识并利用恰当的方式将结果展示给终端用户。

知行智库平台可以从多种渠道来获取和集成数据,确保在国内网站发布后2分钟内采集到,响应速率高达80%。
知行智库平台从全网信息中提取出关系和实体、经过关联和聚合之后采用统一定义的结构来存储这些数据,然后进行清洗,消除噪音或不一致数据,数据质量及可信度高达99%。


知行智库大数据存储使用无结构数据存储,存储引擎使用基于Hadoop生态系统的HBase和Hive。能够让用户在大量的数据中查询记录,并且可以从中获得综合分析报告。
大数据处理的数据类型多种多样,根据需求和场合的不同,知行智库平台运用多种分析技术对数据进行分析,充分满足用户的使用需求帮助用户方便地处理多种数据。


知行智库数据可视化技术,通过将互联网中采集,预处理,存储,分析后的大量多维数据进行整合,使数据集构成数据图像,同时将数据的各个属性值以多维数据的形式表示,可以从不同的维度观察数据,从而帮助用户对数据进行更深入的观察和分析。
知行智库机器学习工具汇集大量优质分布式算法,可高效的完成海量、10 bilion维度数据的复杂计算,给业务带来更为精准的洞察力;同时提供了一套极易操作的可视化编辑页面,大大降低了数据挖掘的门槛,提高建模效率,帮用户快速得到大数据背后隐藏的秘密。

知行智库监督式学习利用逻辑回归和反向传递神经网络将预测结果与“训练数据”进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。
知行智库非监督式学习利用Apriori算法以及k-Means算法,推断出数据的内在结构实现关联规则的学习和聚类分析。


知行智库平台的半监督式学习对未标识数据进行建模,在推理算法和拉普拉斯支持向量机的基础上对标识的数据进行预测。

知行智库平台研发建立大得多也复杂得多的神经网络,运用深度学习算法,来处理存在少量未标识数据的大数据集。
 400-900-8051
400-900-8051
